一、法律遇到了一个它没有准备好的问题
法学和其他社会科学有一个根本的不同:它必须给出答案。
经济学家可以说“这个问题我们还在研究”,社会学家可以说“这个现象需要更多数据”,但当一个真实的纠纷摆在法官面前,他不能说“这个问题法律还没想清楚,我们等一等”。他必须裁判。
这让法学在面对智能体时,处于一种独特的困境:它必须用现有的概念工具处理那些超出这些工具设计范围的情况,而且必须马上处理,因为案子已经来了。
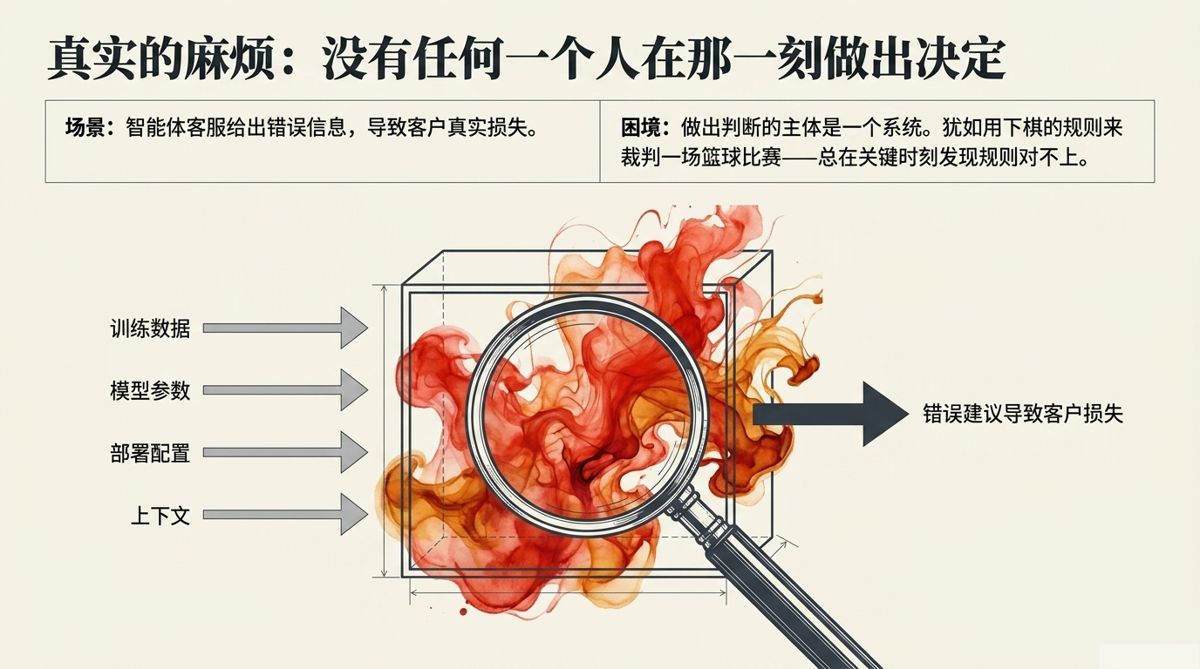
让我描述一种正在真实发生的情形,不是某个具体的案例,而是一类情形的共同结构:一家公司部署了一个智能体,用于处理客户咨询。这个智能体在某一次交互里,给了一个客户一个信息,客户基于这个信息做了决定,结果造成了损失。客户想要追究责任。
这时候,法律遇到了麻烦。
做出那个判断的主体,不是公司的某个员工,不是某个具体的人,而是一个系统——它的行为是由训练数据、模型参数、部署配置以及当时的对话上下文共同决定的,没有任何一个人在那一刻做出了“给这个客户这个建议”的决定。
用现有的法律概念处理这件事,像是用一套为下棋设计的规则来裁判一场篮球比赛——不是完全没有可以借用的地方,但总有一些关键时刻发现规则对不上。
二、法律的历史:永远在事后追赶
法律从来不是预言家。它是历史的记录者——记录哪些冲突发生了,用什么方式解决了,然后把这些解决方案沉淀成规则,以便下次遇到类似情况时有据可循。
这套逻辑在一个变化缓慢的世界里运转得很好。当新的现象出现,法律会用“类推”的方式来处理它:这个新情况最像什么旧情况?把那套规则借过来试试看。如果不合适,在具体的案件里再调整,慢慢积累出新的判例,最终形成专门针对这类情况的法律规则。
这个过程,在汽车出现的时候发生过。汽车是新的,法律最初用“马车”的规则来处理它,慢慢发现不够用,于是逐渐发展出道路交通法、机动车强制保险、产品责任法里专门针对汽车的条款。这花了几十年,期间有大量的混乱和争议,但最终法律大致赶上来了。
智能体的出现,正在触发同样的“类推困境”:法律在寻找最接近的现有类别来处理智能体,但每个类别都不太合适。
类推为“工具”:锤子伤了人,是使用者的责任,不是锤子的责任。如果把智能体当工具,那么它造成的损害,完全由使用它的人或机构来承担。这在某些情况下说得通,但在智能体高度自主运作、运营者无法实时监控每一个输出的情况下,把所有责任压在运营者身上,既不公平,也不能有效激励底层模型开发者提高安全性。
类推为“员工”:雇主对员工在职务范围内的行为负有连带责任——这叫“替代责任”原则,在劳动法里有清晰的规定。智能体在某种程度上确实像一个执行特定职能的“员工”,这个类推有它的吸引力。但员工有法律人格,可以被单独起诉,有自己的权利和义务;智能体没有法律人格,这个类推的基础就缺了关键的一块。
类推为“产品”:产品责任法规定,如果一个产品存在设计缺陷或制造缺陷,导致了使用者损害,制造商承担责任。这对于智能体模型的开发者来说,是一个可能被适用的框架。但“缺陷”在产品责任里有很具体的含义——产品偏离了它应有的设计标准。智能体的“幻觉”和“漂移”,是它在技术上正常运作时产生的行为,不是“偏离设计标准”,这让产品责任的框架很难直接套用。
每一种类推,都能走一段,但都会在某个地方遇到一个关键的不匹配。法律就在这些不匹配里,一次次做出临时的判断,这些判断积累下来,形成了一个内部逻辑并不完全一致的拼图。

三、四个已经在发生的法律麻烦
从抽象的类推问题,落到四个具体的法律领域——这些问题不是将来才会出现的,而是法律系统今天已经在处理,但还没有处理好的。
第一个:法律人格的空白。
现代法律体系里有两种主体:自然人和法人。自然人就是活生生的人,从出生到死亡享有权利、承担义务。法人是法律创造的虚构主体,最典型的是公司——它可以签合同、可以持有财产、可以被起诉,但背后始终有真实的人在控制它、对它负责。
智能体两者都不是。它不是自然人,它也不是法人——它没有股东,没有董事会,没有任何人格意义上的“背后”。它是一个系统,一个过程。
当这个系统以行动者的方式在社会里运作——做推荐、做决策、发起交互、形成实质性的影响——法律体系对它的定性是什么?目前的答案是模糊的:它既不是主体,也不完全是客体,它是某种介于两者之间的存在,而法律体系还没有一个名字来准确描述它。
没有名字,意味着没有清晰的法律地位;没有清晰的法律地位,意味着所有涉及它的纠纷都需要临时决定用哪个框架来处理。这种临时性,在规模扩大之后会产生真实的成本。
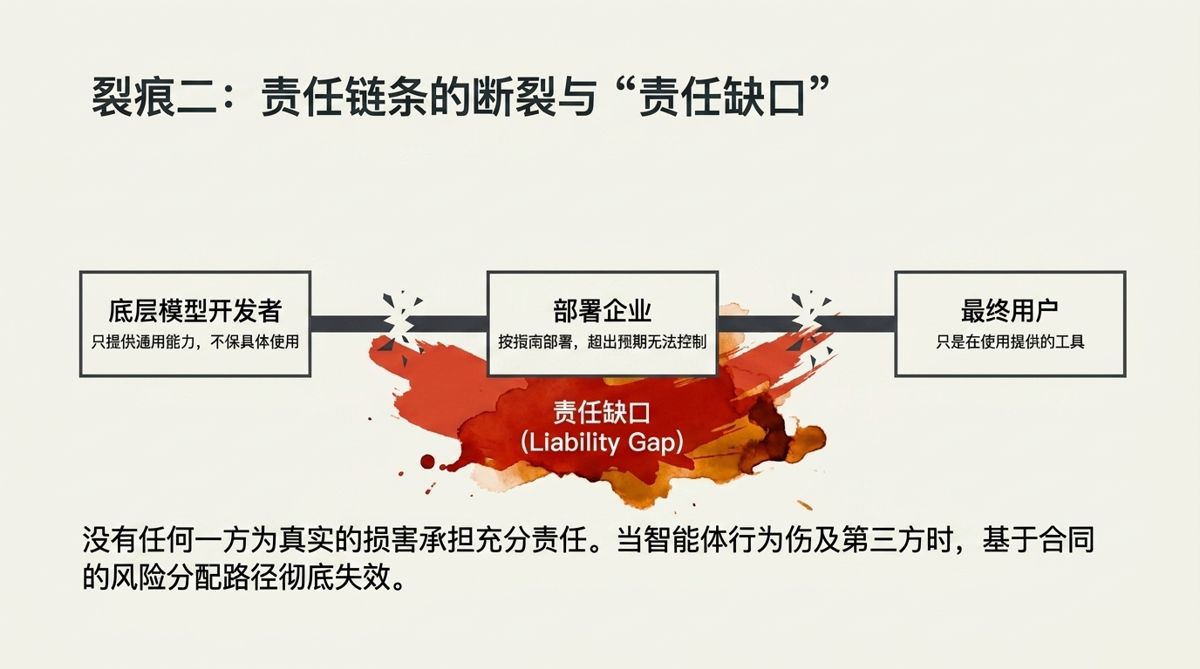
第二个:责任链条的断裂。
当一个智能体造成了损害,法律需要找到“应该负责的人”。但这个链条,在智能体场景里,可能在好几个地方同时断裂。
开发底层模型的公司,声称他们只是提供了通用能力,不对特定的部署方式和使用结果负责。部署智能体的企业,声称他们按照供应商的指南部署,超出预期的行为不是他们能控制的。最终用户,声称他们只是在使用一个被提供给他们的工具。
每一方的说法,单独看都有一定的道理。但加在一起,结果是没有任何一方为损害承担充分的责任。这在法学上叫“责任缺口”——一个真实发生的损害,找不到一个能够被要求充分赔偿的主体。
目前处理这个问题的方式,主要是合同——通过服务条款、使用协议、合同条款来分配风险。但合同只约束签约方,不保护合同之外的第三方。当智能体的行为影响到一个和它没有直接合同关系的人,合同路径就不管用了。
第三个:数据主权在智能体语境里的新难题。
个人数据保护法律,在过去二十年里取得了很大的进展。欧洲的GDPR确立了一系列数据主体的权利,包括“被遗忘权”——你有权要求删除关于你的个人数据。
但这套权利体系,是在“数据存储”的模型下设计的:你的数据被存放在某个数据库里,要删除就从数据库里删掉。
智能体改变了这个模型。当一个模型用包含你个人信息的数据训练过之后,那些信息不是以“可以被查找和删除”的方式存储的,而是以某种弥散的、编码在模型参数里的方式被“记住”了。你如何行使“被遗忘权”?没有一个成熟的技术答案,法律也没有一个成熟的规则回应。
更复杂的情况是,当你在使用智能体的过程中,你的交互历史、你的偏好、你透露的各种信息,被用于改善这个系统——你同意了吗?这个同意是有效的吗?在一个几十页的服务条款里,有一条关于此的说明,算不算有效同意?
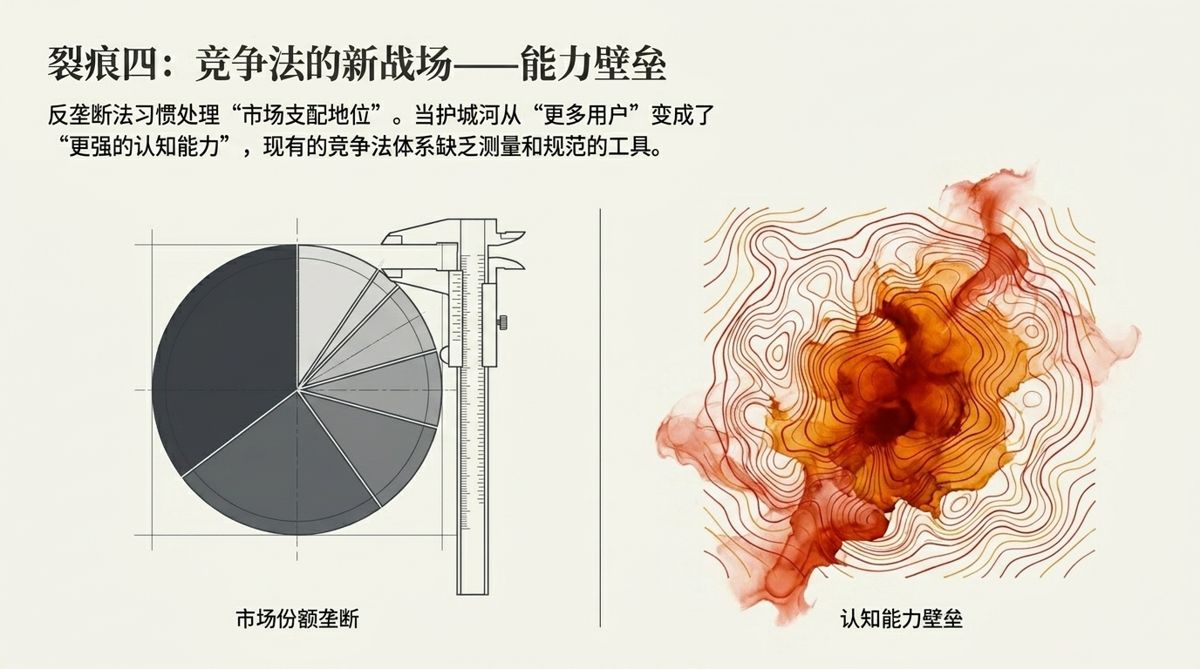
第四个:能力壁垒与竞争法的新战场。
传统的反垄断法,主要处理的是“市场支配地位的滥用”——当一个企业控制了足够大的市场份额,它就有能力排挤竞争者、伤害消费者,这时候反垄断法介入。
但在智能体时代,壁垒不只是市场份额,而是能力本身。拥有最先进模型的机构,不只是有“更多用户”,而是有“更强的认知能力”,而这种能力差距,会以一种旧反垄断框架没有对应概念的方式,形成结构性的竞争壁垒。
如何测量“认知能力”上的市场集中度?如何判断一个智能体系统的能力优势是“正当的竞争优势”还是“滥用市场支配地位”?这些问题,现有的竞争法体系没有工具来处理。
四、法律的本质难题:它总是在事后
把这四个问题放在一起,有一个共同的深层逻辑:法律处理问题的方式,本质上是“事后的”。它需要等到冲突真实发生,在具体案例里积累判例,才能形成规则。这套逻辑在变化缓慢的世界里是有效的,因为“事后”的时间间隔不长,规则能够赶上现实。
但智能体进入社会的速度,比法律积累判例、形成规则的速度快得多。这意味着在法律体系追上来之前,会有一段相当长的时间,在这段时间里,所有涉及智能体的纠纷,都在一个规则不清晰的状态下被处理。
这段时间里,谁的利益受损最大?通常是那些在纠纷中议价能力最弱的一方。历史上每一次法律滞后的阶段,代价都不是平均分担的。
有没有可能这次做得更好?在损害大规模发生之前,主动建立智能体的法律框架,而不是等到足够多的案例积累之后再回头建立?
从历史规律看,这非常难。主动立法需要政治意志,政治意志需要足够广泛的社会认知,而社会认知的形成通常需要真实的、有显示度的损害作为触发器。这是一个令人沮丧的循环。
但这个循环也不是铁板一块的。历史上确实存在少数成功的“预防性”立法,它们往往发生在一个特定的条件下:有足够多的人能够清晰地预见到即将到来的问题,并且有能力把这个预见转化为有说服力的政策建议。
这大概是为什么,把智能体面临的法律问题说清楚,不只是法学家的工作。
五、一个诚实的承认
写完这篇,我想说一件实话:法律问题是这个系列里我最不专业的领域。我不是法学家,以上这些分析,是一个在实践里碰到这些问题的从业者的观察,不是受过严格法学训练的人的判断。
我写这篇的目的,不是提供答案,而是描述问题的位置:这些法律空白存在于哪里,为什么现有的概念工具不够用,为什么这件事需要被认真对待。
如果这些描述能够让更多真正懂法律的人觉得“这件事确实值得认真研究”,这篇文章就达到了它的目的。
法律是所有社会制度里最贴近现实的那一层。它不能停留在“这个问题很复杂”的层面,它必须最终给出一个可以执行的答案。正是这种“必须给答案”的特性,让法律成为衡量社会对一个新现象准备程度的最诚实的指标。
从这个标准看,我们今天面对智能体,还没有准备好。
最后一篇,我们把视角从社会的各个维度,转向一个更具体的结构:当大量智能体开始相互连接、相互调用,会涌现出什么?
